コンピュータビジョンベースの手話翻訳
東京オリンピック2020が開幕しました。開会式のテーマは「多様性」。ラストの聖火台点灯の大阪なおみ選手の姿が印象的でした。国籍、人種、性別、年齢、障害、宗教等の違いによらず、多様な価値観による多様性の調和に向けた取り組みを、私たち日本人は歩み始めたばかりです。オリンピックに続き、パラリンピックが予定されています。障害の有無に関係なく、アスリートたちの挑戦は、私たちに感動を与えてくれます。今回は、手話ユーザと、口頭や筆談、別の手話ユーザとの間の対話のための、コンピュータベースの双方向翻訳に関する発明です(US20210174034、SIGNALL TECHNOLOGIES)。
コミュニケーション手段としての手話
人間が社会生活を送る上で、他者とのコミュニケーションをとることは欠かせません。例えば、日常生活では、家族や近隣の人々、友人や知人との暮らしを豊かにするためのコミュニケーション。ビジネスでは、上司や部下との情報共有や共同作業、取引先やビジネスパートナーへのプレゼンテーションや商談などのコミュニケーションなど。辞書を引くと、コミュニケーションとは「意思の疎通」とあります。一方向でなく双方向で、双方の関係に応じたコミュニケーションを行い、お互いの意思が伝わることです。
コミュニケーション手段は、音声や文字、ジェスチャーなど様々な手段があります。オリンピックで生まれたピクトグラムもコミュニケーション手段の一つと言えます。その中でも、手話は、聴覚障害者にとって、なくてはならないコミュニケーションの手段です。しかし、健常者で手話を理解できる人はほとんどいません。これからの多様化社会では、聴覚障害者と健常者とが、当たり前のように、コミュニケーションをとることができる社会が望まれます。AI技術の革新により、様々な言語の自動翻訳が実現されました。そしてさらに、聴覚障害者とのコミュニケーションを促進するための、手話の音声や文字へ自動翻訳の開発が待たれています。
手話を翻訳するにはさまざまな課題があります。関連するすべての側面を考慮して、会話全体を把握しなくてはならない場合があり、手話者が使用するスペースと、全体の状況を考慮しなくてはなりません。手話で発話されたフレーズまたは表現は、それが終了した後にのみ認識および理解することができる場合があり、時間的側面も注意する必要があります。また、発話間の境界は曖昧なことが多く、会話の文法的および意味的なコンテキストによってのみ理解される場合もあります。これらの課題により、部分的にしか翻訳できない可能性があります。手話は、話し言葉や書き言葉とは異なり(手話の種類によって異なるため)、文法上の違いに悩まされることもあります。
コンピュータベースの手話の双方向翻訳
この発明は、手話による発話をターゲット言語に翻訳する方法の発明です(US20210174034、SIGNALL TECHNOLOGIES)。
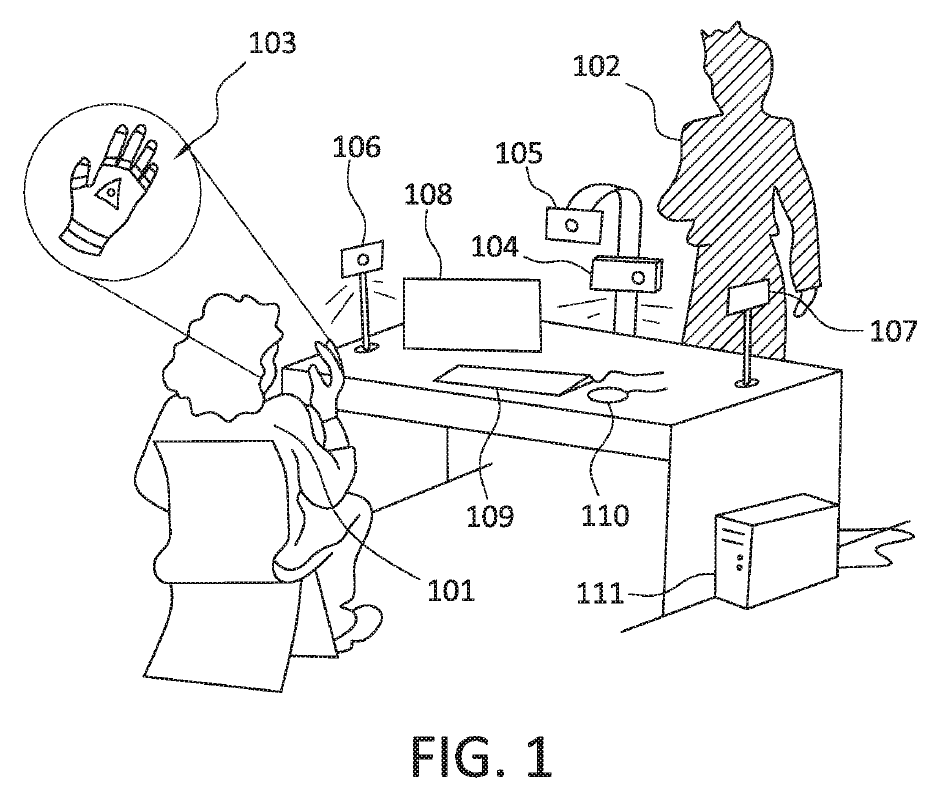
Fig.1は全体イメージ図、Fig.3はこの発明の全体構成とフローを示します。
手話発話の処理のレイヤー構造と、レイヤー間のインターフェイスでの関連データが示されています。符号発話の処理は、それぞれが構成要素に対応し得るより小さなタスクに分解されます。
これらのタスクの処理は、時間的に互いに重複する可能性があるため(通常は重複する可能性があります)、これらのコンポーネントはレイヤーと呼ばれる場合があります。
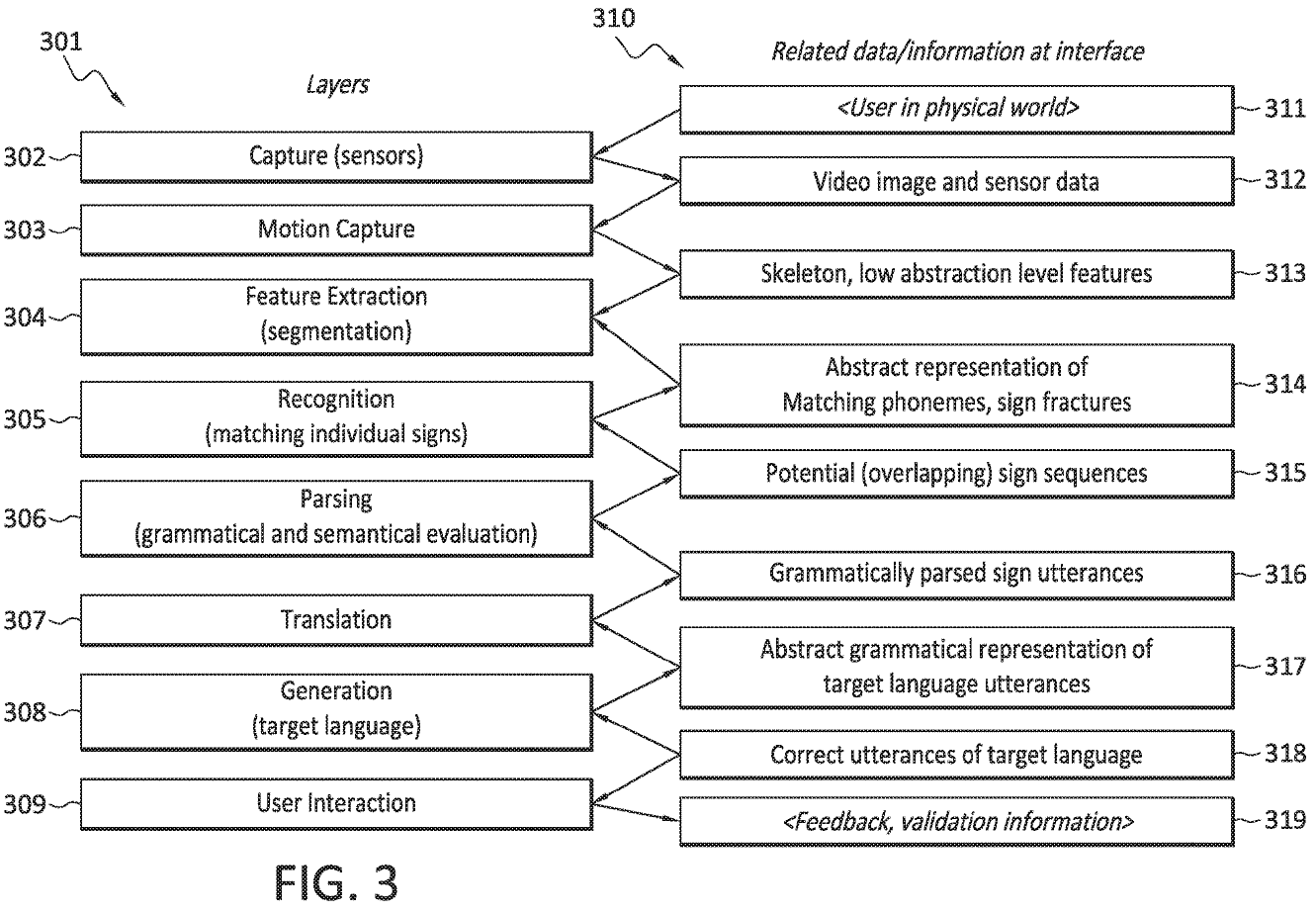
- キャプチャ層(302)
光学/画像センサ、カメラまたは3Dカメラなどでシーンをキャプチャします。 - モーションキャプチャ層(303)
ユーザの動きをより抽象的なデータにキャプチャします。ユーザの骨格モデルの関節の位置および向き、顔のマーカー、直接の顔の特徴、手の形、可能な手の構成など。 - 特徴抽出層(304)
モーションキャプチャ層から「生の」モーションキャプチャデータを取得し、それを、手話の様々な側面のキャプチャされた動きを表す音素およびサインフラクチャデータ(314)に変換することができます。 - 認識層(305)
音素の間隔に符号を一致させ、サインフラクチャデータ(314)符号を一致させる - 構文解析層(306)
電位符号系列データ内の可能な符号インスタンスを解析し、解析された手話発話の抽象的表現にそれを評価します。これらの解析された署名された発話は、会話のコンテキストとの文法的な正確さと意味的な互換性によって評価および検証されます。 - 翻訳層(307)
解析された手話発話をターゲット言語発話(317)としてターゲット言語に翻訳します。 - 生成層(308)
ターゲット言語発話(317)の翻訳された表現を使用して、ユーザによって知覚される適切なターゲット言語表現(318)を生成します。ターゲット言語表現は、書かれたターゲット言語の場合はテキスト、話されたターゲット言語の場合は音声/生成されたスピーチ、およびターゲット手話の場合は視覚的表現(例えば、動くアバター)を含みます。 - ユーザインタラクション層(309)
ターゲット言語表現のユーザに、ユーザが知覚することができ、ターゲット言語表現に応答してシステムと対話することができるように、ユーザーインタラクション層に提示されます。ディスプレイに表示するか、音声表現のためにスピーカーを使用します。
手話翻訳のためのマーカー用グローブ
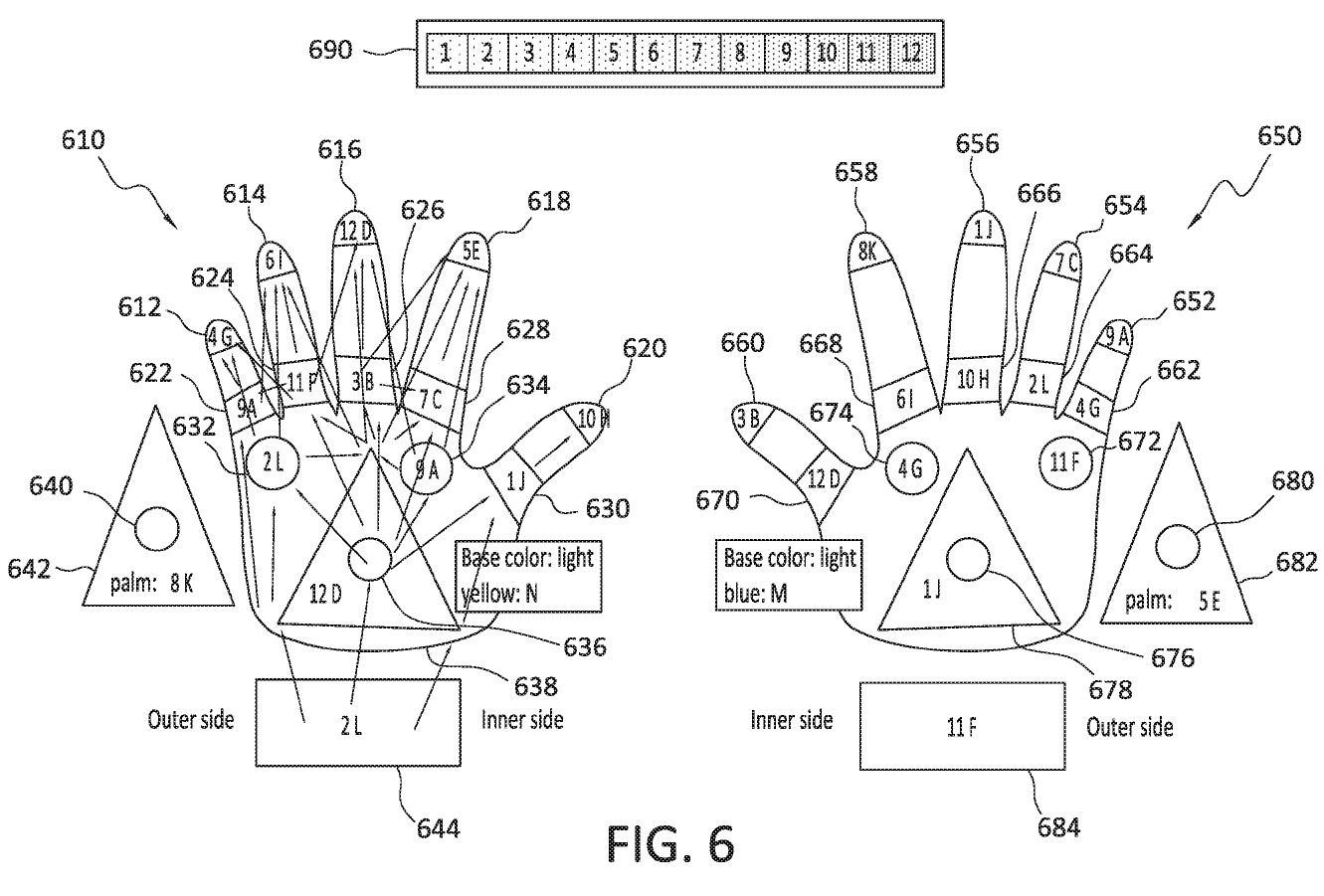
Fig.6は、手に適切なマーカーを提供する手段として使用される、手話翻訳のためのツールです。左手袋の背面(610)、右手袋の背面(650)は、手袋に使用されているさまざまな色を示しています。
各色は、モーションキャプチャ層(303)によって容易に検出されやすいように、特定の色を有しています。マーカーの配置は、手話に重要な手の位置、例えば、指先、手首、手のひらの中心、手の甲の中心、手の刃に対応します。追加のマーカーは、マーカーの位置が指の構成をより正確に定義する配置で使用することができ、例えば、指の曲がりを検出するために複数のマーカーを指に使用することができます。マーカーは、明確な方向、または検出可能なコーナー、およびマルチカラーのマーカーとともに使用することもできます。
手話発話処理のタイミング
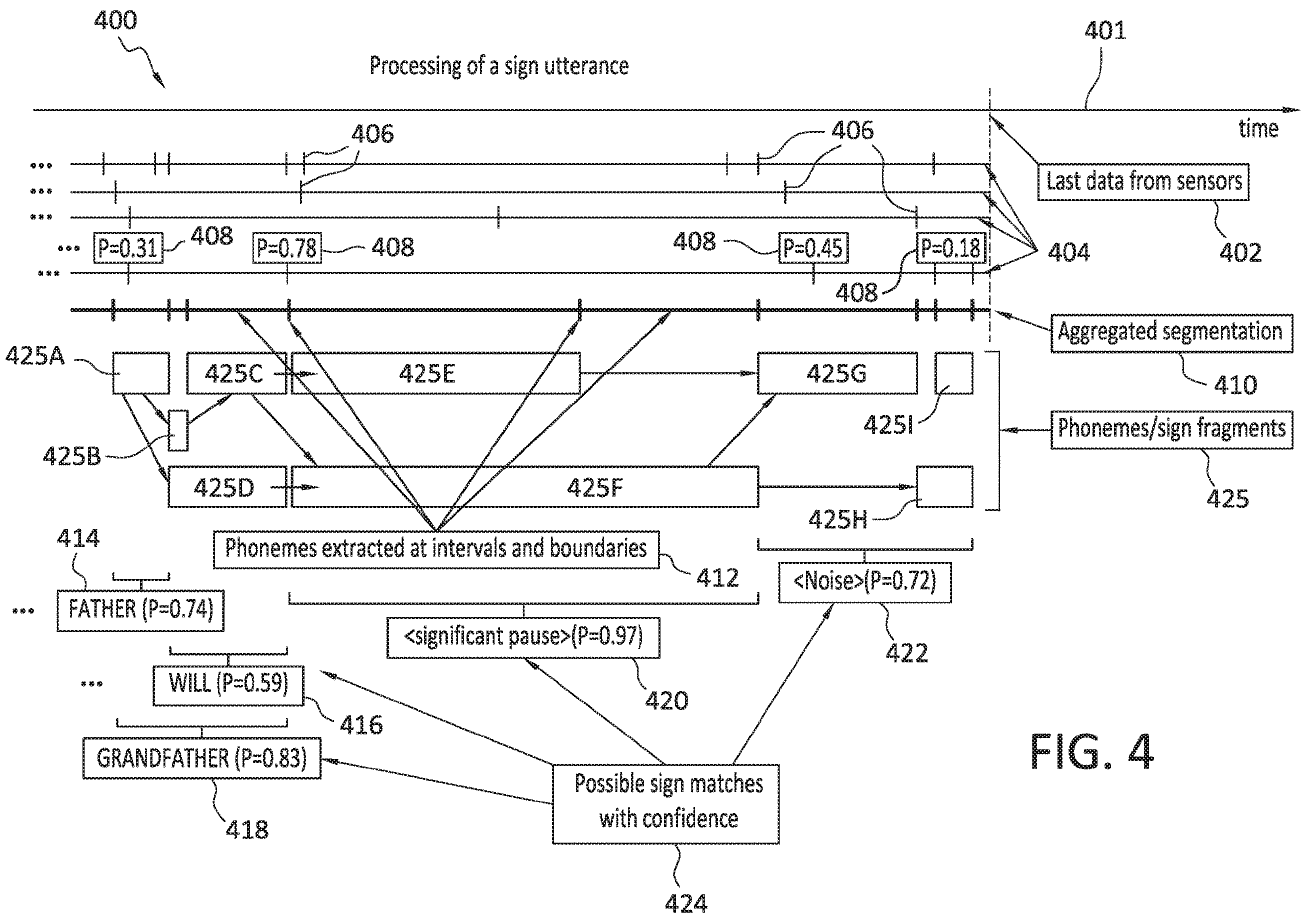
Fig.4は、サイン発話の処理のタイミングを示します。
この翻訳システムの特徴は、手話サインごとに処理しないという点です。手話の連続会話の発話を、動的にバッチ処理します。時間の経過を示すタイムライン401が上部に示されています。垂直線402は、発話の最後のデータがセンサから受信された時間を示します。次に、特徴抽出層304から抽出された特徴のそれぞれについて、タイムライン404が示されています。これらの抽出された特徴404のそれぞれは、406によって示されるようにセグメント化されます。また、信頼度408は示された境界が正しいという信頼度を推定する各セグメントに関連付けることができます。機能の時間的セグメンテーションは、さまざまなタイプの機能に対して個別に処理されます。たとえば、各手の動き、顔の特徴、および体は独立してセグメント化されます。
手話にチャレンジしたことがある、という人は比較的多いと思います。しかし、(私もその一人ですが)、長続きせず身につかなかった経験が多いのではないでしょうか。多言語翻訳がリアルタイムに使用できるようになった現在、手話翻訳がスマホの機能の一つとして実現される、そんな日は近いのではないでしょうか。